Regularization
정규화는 모델이 훈련 데이터의 잡음을 학습하고 보이지 않는 데이터에서 성능이 저하될 때 발생하는
과적합을 방지하기 위해 기계 학습에 사용되는 기술입니다.
overfitting
과적합(overfitting)은 훈련 데이터에 너무 잘 맞는 복잡한 모델로 이어질 수 있지만 새로운 예제로
일반화되지는 못합니다.


underfitting




이 문제를 해결하기 위해 정규화는 손실 함수에 페널티 항을 추가하여 모델이 단일 기능에 너무 많은 중요성을 할당하거나 너무 복잡해지는 것을 방지합니다.
가장 일반적인 두 가지 정규화 방법은 L1(Lasso) 및 L2(Ridge) 정규화입니다.
제 1 정규화
L1 정규화는 모델 가중치(계수)의 절대값을 손실 함수에 추가하여 일부 기능 가중치를 0으로 유도하여 모델의 희소성을 장려합니다.
그 결과 더 적은 기능에 의존하는 더 단순한 모델이 생성되어 과적합이 줄어들고 해석 가능성이 향상됩니다.

제 2정규화
L2 정규화는 모델 가중치의 제곱을 손실 함수에 추가하여 가중치를 축소하지만 반드시 0으로 만들지는 않습니다. 이렇게 하면 모델이 단일 기능에 너무 많이 의존하는 것을 방지하여 과적합을 줄이고 보다 균형 잡힌 모델로 이어집니다.

정규화의 이점:
- 과적합 감소: 정규화는 모델이 너무 복잡해지고 교육 데이터에 너무 잘 맞는 것을 방지하여 보이지 않는 데이터에 대한 일반화를 개선합니다.
- 일반화 개선: 페널티 항을 통합함으로써 정규화는 모델이 특정 예를 암기하는 대신 데이터의 기본 패턴을 학습하도록 장려하여 새 데이터에 대한 성능을 향상시킵니다.
- 기능 선택(L1): L1 정규화는 일부 기능 가중치를 0으로 유도하여 모델에서 이러한 기능을 효과적으로 제거하여 가장 중요한 기능을 식별하고 해석 가능성을 개선하는 데 도움이 될 수 있습니다.
정규화의 단점:
- 과소적합을 일으킬 수 있음
- 정규화 기간이 너무 크면 모델에 과도한 불이익을 주어 모델이 너무 단순해지고 데이터의 기본 패턴을 캡처할 수 없어 과소적합이 발생할 수 있습니다.
- 정규화 매개변수 조정 필요: 정규화는 페널티 기간의 강도를 제어하는 하이퍼 매개변수를 도입합니다.
- 이 매개변수는 과소적합과 과적합 사이의 올바른 균형을 찾기 위해 조정되어야 합니다.
- 이는 시간이 많이 걸리고 교차 검증 또는 기타 모델 선택 기술이 필요할 수 있습니다.

요약하면, 정규화는 과적합을 방지하고 모델의 일반화를 개선하기 위한 기계 학습의 필수 기술입니다. 손실 함수에 페널티 항을 추가함으로써 정규화는 모델이 너무 복잡해지고 개별 기능에 지나치게 의존하지 않도록 합니다. 그러나 정규화는 과소적합의 위험 및 하이퍼파라미터 튜닝의 필요성과 같은 새로운 문제도 도입합니다.
Database normalization
데이터베이스 정규화는 데이터 중복을 줄이고 데이터 무결성을 향상시키기 위해 관계형 데이터베이스 설계에 적용되는 프로세스입니다.
정규화의 목표는 삽입, 업데이트 및 삭제 이상과 같은 데이터 이상 가능성을 최소화하면서 각 테이블이 단일 엔터티 및 관련 특성을 나타내는 방식으로 데이터베이스 스키마의 데이터를 구성하는 것입니다.
데이터베이스 정규화는 제1정규형(1NF), 제2정규형(2NF), 제3정규형(3NF)과 같은 일련의 정규화 형식을 통해 이루어집니다.
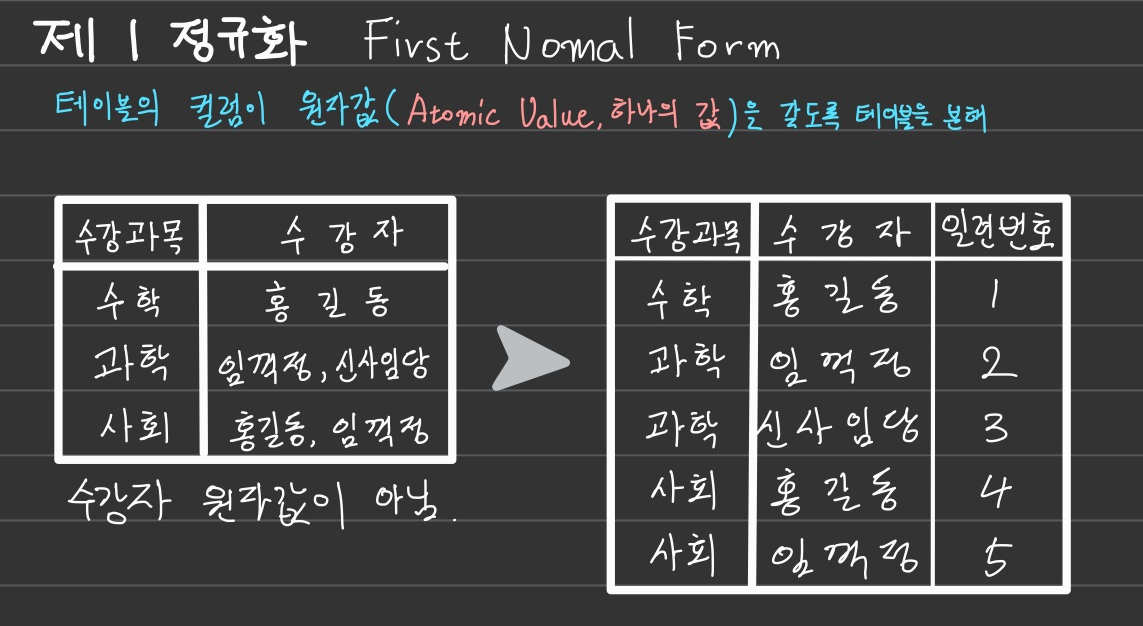
제 1 정규화 (First Normal Form)

-
발생할 수 있는 이상(Anomaly)의 예
-
갱신이상: 홍길동이 사회과목을 ‘역사’로 바꾸었다. 그럼 임꺽정이 듣고 있는 사회 과목도 바뀌어버린다.
- UPDATE 과목 SET 수강과목 = ‘역사’ WHERE 수강과목 = ‘사회’ AND 수강자 = ‘홍길동’
-
삭제 이상: 임꺽정이 ‘과학’ 과목을 수강취소했다. 그럼 신사임당의 수강 정보도 삭제된다.
- DELETE FROM 과목 WHERE 수강과목 = ‘과학’ AND 수강자 = ‘임꺽정’
-
갱신이상: 홍길동이 사회과목을 ‘역사’로 바꾸었다. 그럼 임꺽정이 듣고 있는 사회 과목도 바뀌어버린다.
제 2 정규화 (Second Normal Form)

- 학번 <-> 이름+소속+학과장은 종속 관계가 있다.(한 학과내의 이름은 중복되지 않는다고 가정)
- 하지만 사실 학과장은 소속학과 하나만에도 종속(소속학과 <-> 학과장)되므로 이는 부분적인 종속관계가 포함되어 있다.
- 즉 학과장은 꼭 이 릴레이션에 있어야 할 필요도 없고, 이 릴레이션에 있는 순간 ‘김교수’와 같이 계속 중복적재 될것이다.
-
지도교수 사무실도 학번에 종속
-
발생할 수 있는 이상(Anomaly)의 예
- 삽입이상: 컴퓨터과, 전자과, 기계과 학생을 추가하고자 할 경우 더이상 불필요한 중복정보인 학과장 정보가 삽입되야 한다.
- 갱신이상: 컴퓨터과의 학과장이 변경되었다. 하나만 변경하면 모순이 발생하므로 다 찾아서 변경해야 한다.
- 삭제이상: 신사임당이 자퇴해서 삭제하고자 한다. 이 삭제로 인해 기계과 학과장의 정보가 사라져버린다.
제 3정규화 (Third Normal Form)

-
발생할 수 있는 이상(Anomaly)의 예
- 삽입이상: 컴퓨터과, 전자과 학생을 추가하고자 할 경우 더이상 불필요한 중복정보인 대학 정보가 삽입되어야 한다.
- 갱신이상: 컴퓨터과의 소속 대학이 ‘IT대학’으로 변경되었다. 하나만 변경하면 모순이 발생하므로 다 찾아서 변경해야 한다.
- 삭제이상: 홍길동이 자퇴해서 삭제하고자 한다. 이 삭제로 인해 컴퓨터과의 대학 정보가 사라져 버린다.
BCNF (Boyce and code Normal Form)

- 제약사항
- 한 학생은 동일한 과목에 대해 한교수에게만 수강가능
- 각 교수는 하나의 과목만 담당
- 한 과목은 여러 교수가 담당가능
- 분석
- (학번 + 과목)은 교수를 결정 짓는다.
- 교수는 과목을 결정 짓는다.
- 즉, 교수 또한 결정자인데 교수는 학번을 결정 지을 수 없으므로 후보키는 아니다.
-
발생할 수 있는 이상(Anomaly)의 예
- 삽입이상: 200학생이 데이터베이스를 수강하고자 할 경우, 현재 불필요한 홍길동 교수 정보가 한번 더 삽입된다.
- 갱신이상: 홍길동의 담당 과목이 알고리즘으로 바뀌었다. 담당 과목을 변경할 경우, 학생의 수강 과목이 변경되어 버린다.
- 삭제이상: 300학생이 자퇴해서 삭제하고자 한다. 이 삭제로 인해 인공지능 과목을 유관순 교수가 담당하고 있다는 정보가 사라진다.
데이터베이스 정규화의 장단점
장점
- 데이터 무결성
- 정규화는 데이터에 대한 일관된 구조를 적용하여 삽입, 업데이트 및 삭제 이상과 같은 데이터 이상 가능성을 줄입니다.
- 데이터 무결성을 유지하고 불일치를 방지하는 데 도움이 됩니다.
- 데이터 중복성 감소
- 데이터를 엔터티 및 해당 관계를 기반으로 별도의 테이블로 구성함으로써 정규화는 중복 데이터를 제거하고 스토리지 요구 사항을 줄이고 데이터 관리를 단순화합니다.
- 향상된 쿼리 성능
- 정규화된 데이터베이스에는 종종 더 작고 집중된 테이블이 있어 더 효율적인 쿼리 실행으로 이어질 수 있습니다.
- 인덱싱 및 쿼리 최적화는 각 테이블의 특정 요구 사항에 더 잘 맞출 수 있습니다.
- 단순화된 데이터베이스 스키마
- 정규화는 데이터에 대한 논리적 구조를 적용하여 엔터티와 특성 간의 관계를 더 쉽게 이해할 수 있도록 합니다.
- 데이터베이스 유지 관리 및 개발을 단순화합니다.
- 더 쉬운 수정 및 확장
- 정규화된 데이터베이스 스키마는 더 유연하여 데이터베이스의 다른 부분에 영향을 주지 않고 더 쉽게 수정 및 추가할 수 있습니다.
단점
- 복잡성 증가
- 정규화로 인해 테이블 수가 많아져 데이터베이스 스키마의 복잡성이 증가하고 이해 및 작업이 더 어려워질 수 있습니다.
- 느린 쓰기 성능
- 정규화된 데이터베이스는 종종 데이터 검색을 위해 더 많은 조인을 필요로 하므로 변경 사항이 여러 테이블에 전파되어야 하므로 쓰기 성능이 느려질 수 있습니다.
- 쿼리 복잡성 증가
- 정규화된 데이터베이스의 쿼리에는 더 많은 조인이 포함될 수 있으므로 쿼리가 더 복잡해지고 쓰기 및 최적화가 더 어려워질 수 있습니다.
- 잠재적인 성능 문제
- 정규화가 경우에 따라 쿼리 성능을 향상시킬 수 있지만 관련된 조인 및 테이블 수 증가로 인해 성능 문제가 발생할 수도 있습니다.
- 이를 해결하려면 신중한 인덱싱, 쿼리 최적화 또는 비정규화가 필요할 수 있습니다.
결론적으로 데이터베이스 정규화는 향상된 데이터 무결성, 중복성 감소, 단순화된 데이터베이스 스키마와 같은 몇 가지 이점을 제공합니다.
그러나 복잡성 증가, 쓰기 성능 저하, 잠재적인 성능 문제와 같은 몇 가지 단점도 있습니다. 데이터베이스 정규화에 대한 결정은 응용 프로그램의 특정 요구 사항과 장단점 간의 균형을 기반으로 해야 합니다.
Regularization : 모델이 훈련데이터를 학습하고 성능이 저하될 때 발생하는 과적합을 방지하기 위해 기계 학습에 사용되는 기술, 모델이 너무 복잡해지거나 개별 기능에 너무 많은 중요성을 할당하는 것을 방지하여 모델의 일반화를 개선하며, L1(Lasso) 및 L2(Ridge) 정규화와 같은 기술은 주로 기계 학습 모델의 성능 및 안정성을 개선하는 것과 관련됨
DB Normalization : 데이터 중복을 줄이고 무결성을 향상시키기 위해 RDBS 설계에 적용되는 프로세스 Error 가능성을 최소화하면서 각 테이블이 엔터티 및 관련 특성을 나타내는 방식으로 DB 스키마의 데이터를 구성하는 것 제1정규형(1NF), 제2정규형(2NF), 제3정규형(3NF), BCNF 정규형 등 일련의 형식을 통해 이루어짐
장점 : 무결성, 중복성 감소, 향상된 쿼리, 단순화된 DB, 더 쉬운 수정 및 확장 단점 : 복잡성 증가, 느린 쓰기 성능, 쿼리 복잡성 증가, 잠재적인 성능 문제